Wir müssen wissen, wir werden wissen! (We must know. We will know.)
David Hilbert
I am working on the foundations of learning, including mathematical and statistical modeling and inference on non-Euclidean data, and mathematical and statistical foundations of neural network models. These research topics will use a variety of tools in mathematics, including real/complex/functional/harmonic analysis, measure/probability theory, (stochastic) differential/integral equations, differential geometry, and topology.
Any of the following topics can be made into a project or thesis topic for Master’s or PhD degree in Statistics or Mathematics.
A. Overview
- Interaction between algebra, geometry, topology and statistics: The Euclidean space is a topological space, an additive group, a metric space, a manifold, and a vector space, for which these 5 structures are compatible. This is why we can do nice statistics and probability theory in the Euclidean space. Suppose we remove the vector space structure from the Euclidean space, then linear models cannot be defined any more (globally); suppose we remove the additive group structure from the Euclidean space, then additive models and location-shift distributions cannot be defined any more; suppose we remove the manifold structure from the Euclidean space, then the central limit theorem may not hold anymore and the second pillar of statistics collapses; suppose we remove the metric structure from the Euclidean space, then the Glivenko–Cantelli theorem theorem may not hold any more and the first pillar of statistics collapses. In fact, without a metric or group structure, pretty much little statistics can be done. However, there are many real world data sets whose modeling data spaces lack one or several of the 5 structures mentioned earlier. So, a natural question is “To conduct sensible statistical inference and/or modeling, what are the needed minimal requirements on the algebraic, topological and/or geometric structures on the data space?”
- Statistics for neural networks (and in particular, deep convolutional neural networks (CNNs)) and study of “big models”: Deep CNNs have demonstrated remarkable precision in binary classification (and other prediction) tasks. However, they belong to the class of models, which I call “big models”, whose complexities are far beyond “small models” that have been the dominant ones in statistics. Little is known on the non-asymptotic statistical properties of CNNs, even though they possess certain symmetries. In general, statistics has just started studying “big models” in the era of “big data “, and there is a lot to be done for them.
- Connections between subspace or manifold estimation and variational inference: There seems to be a hidden path between subspace and manifold hidden in a statistical or probability model and local optima of a complicated objective function of variational inference. This path can lead to magnitudes of speed increase in variational inference without sacrificing accuracy much.
- Proportion estimation for null hypotheses of statistical models on Lie groups: This is a significant extension of the research on proportion estimation in Euclidean space, and it will use probability theory and harmonic analysis on Lie groups. Please refer to “proportion estimation” in Remaining Research.
- Proportion estimation for null hypotheses of statistical models for Bayesian mixture models: This is an application of the methods and theories I developed to Bayesian mixture models. Please refer to “proportion estimation” in Remaining Research.
- Numerical implementation of proportion estimators: This is related to numerical implementation of proportion estimators I have developed, and requires error bounds on a Riemann sum of a smooth, oscillating function none of whose derivative of any order is uniformly bounded on any compact set of the domain of integration of this function. Please refer to “proportion estimation” in Remaining Research.
- Regression models between a metric space and Lie group and variable/model selection: This is probably the most general setting where a regression model can be formulated with structured covariates-response relations. It is an extension of Prof. Hans-Georg Müller’s Frechet regression.
- Classify probability measures on Euclidean space whose Fourier transforms have no real zeros: This is related to a condition used in the construction of proportion estimators by harmonic analysis and is connected to an equivalent formulation of the Riemann Hypothesis. Please refer to “proportion estimation” in Remaining Research.
- Control of multiple error criteria in multiple testing: Most works in multiple testing control one error criterion such as the k-FDR or k-FWER without necessarily ensuring power at a prespecified level. However, in practice there are situations where we need to control multiple error criteria simultaneously or control the same error criterion on different “layers” or “groups” of hypotheses when taking into consideration structures of a set of hypotheses and at the same time ensure a prespecified power level. Needless to say, this is a very challenge task since there are examples of procedures that optimize for an error criterion and a power criterion but behave unstably or insensibly. Further, this is related to multiple testing structured hypotheses, which is a current trend in multiple testing. Please refer to Remaining Research.
- FDR control under dependence: Up till now, we are only aware of two types of dependence, namely, PRDS and reverse martingale, for which the famous Benjamini-Hochberg (BH) procedure is conservative. It is known that BH procedure is not conservative when, e.g., PRDS is reverted. So, a natural question is “Can we identify another type of dependence for which the BH procedure is conservative?” or “How can we modify the step-up critical constants of the BH procedure nontrivially to account for dependence and maintain FDR control?” On the other hand, there is considerable numerical evidence that some adaptive FDR procedures are conservative under positive dependence even though they have not been theoretically proven so. So, a natural question is “Can we prove that they are actually under such dependence?” or “Can we classify distributions or nontrivial dependence structures that satisfy conditional PRDS?” This is basically the conjecture that there are other types of dependence under which BH procedure is conservative. Also, we need to statistically test whether hypotheses that ensure FDR control under dependence are plausible. Please refer to “Multiple testing under dependence” in Remaining Research.
B. Foundations for Analysis of non-Euclidean Data
1. Uniqueness of Frechet mean
General motivating question: Which statistics for a probability measure in Euclidean space can we generalize when the space is a metric space, so that these generalizations are amenable for mathematical analysis and statistical applications?
The concept of “expectation”, also known as “mathematical expectation” or “mean”, is one of the most fundamental concepts in statistical learning and probability theory. It is a core for inference and modelling, on which so many methods and theories in statistical learning and a significant part of probability theory have been built. These include one-/two-sample tests, regression models (as special cases of estimating stratified spaces that are formed by “conditional expectation”), laws of large numbers and central limit theorems (as special cases of concentration of measures around “expectation” for empirical processes), etc.
Our most familiar definition of “expectation” is the one for a probability measure in a Euclidean space, which is a topological space, an additive group, a metric space, a manifold, and a vector space. However, there are data that cannot be well modeled by Euclidean space, as the following slide illustrates:
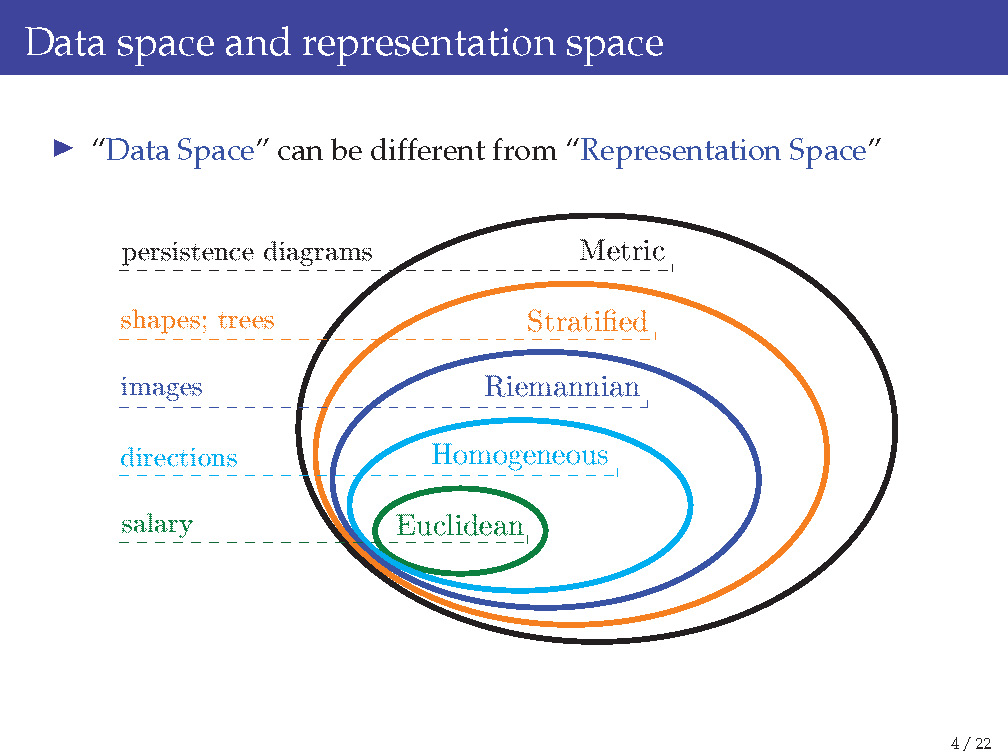
Once we are not in a Euclidean space and consider, e.g., a group, how do we even define “expectation” for a probability measure on it? Well, things are quite different from Euclidean space, and sometimes quite strange. Lacking needed structures is the key obstacle behind all these.
The question of “When does a probability measure on a metric space of non-negative sectional curvature have a uniquely defined “expectation?” is a very, very hard question. So, let us focus on “expectation” in a Riemannian manifold of non-negative sectional curvature. The latter is the realm that I am much more familiar with and has been working on for around 3 years. I have creatively found some potential strategies to address the uniqueness problem, and know their deep connections with the theory of differential equations (in particular, singularity of the differential of exponential mapping on a Riemannian manifold), algebraic and differential topology (in particular, critical points and level sets of a Lipschitz function on a Riemannian manifold), and harmonic analysis (in particular, on a Riemannian homogeneous space or on the isometry group of a Riemannian manifold).
The following slide summarizes the main causes of the difficulty and tools needed to address it:
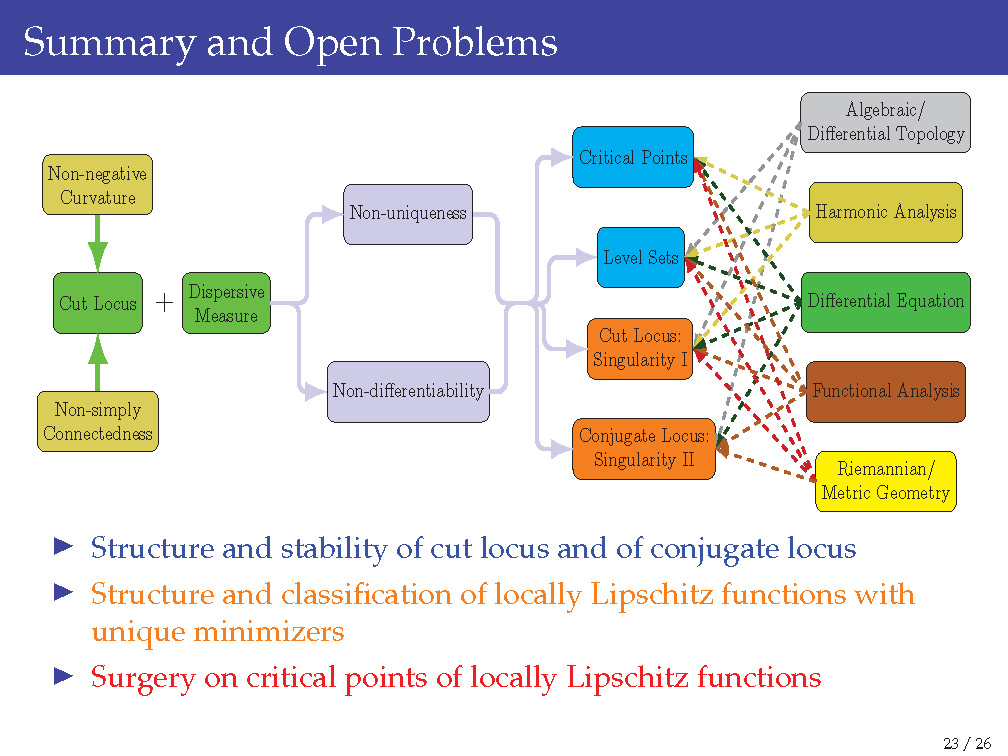
I have proposals to deal with the uniqueness problem. Please reach out to me if you would like to work with me or collaborate with me. Two simplest settings of the uniqueness problem are given below:
- Classification of measures on the 2-sphere with unique Frechet mean.
- Classification of measures on symmetric spaces with unique Frechet mean.
2. Estimating geodesic distance and curvature
General motivation question: Given a data set, which geometry to use for analysis?
There are two perspectives on what geometry is: one from Flex Klein, which roughly states the geometry is the study of invariant actions and gave birth to the famous Erlangen program, and the other from Bernhard Riemann, which roughly states that geometry is a variational problem.
Take networks as describing binary relationships for example, where each network is an observation and is formulated as a matrix. People have found out that “embedding” these matrices into a hyperbolic space can reveal more informative structures than just “embedding” them into a Euclidean space.
C. Mathematical and Statistical Foundations of Deep Learning
General motivation questions: What does a deep neural network learn? How does a deep neural network learn?
The following two slides summarize why it is quite difficult to answer either of these two questions:
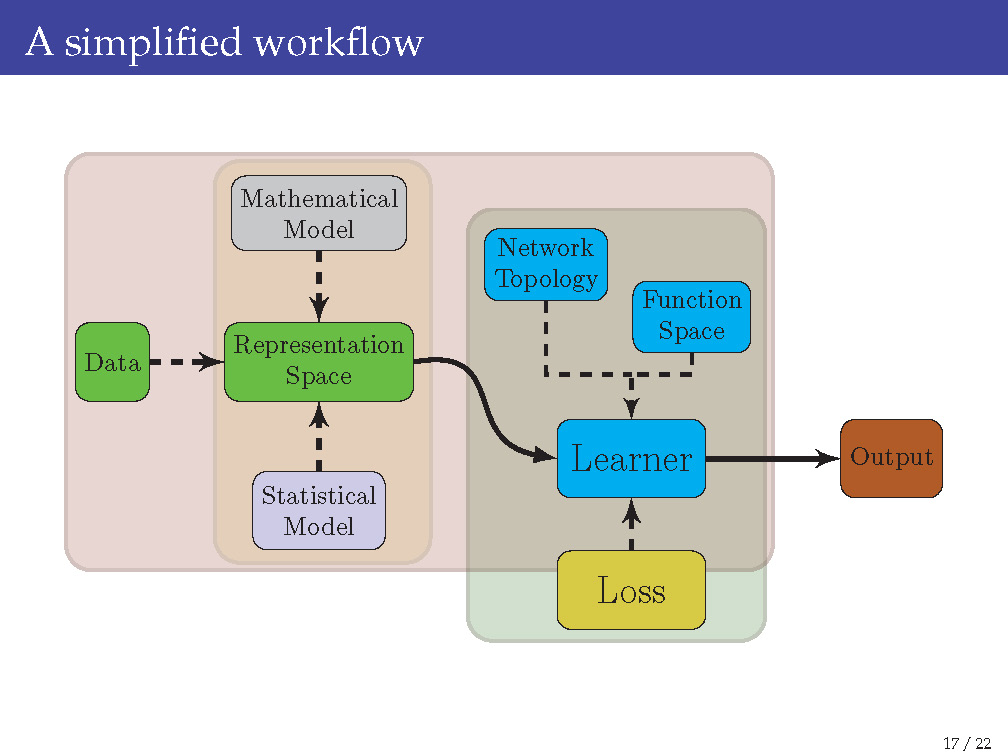
This is a vast research topic that branches into almost all subfields of statistics and mathematics and contains the following 4 subtopics of research:
1. Statistical and probabilistic models for data
There is almost no statistical or probability model for data sets, e.g., handwritten digits, that have been analyzed by deep neural networks. From the perspective of statistical learning, the “data distribution” is missing. Without a data distribution, we cannot formally and accurately quantify the “test error” of a deep learning method.
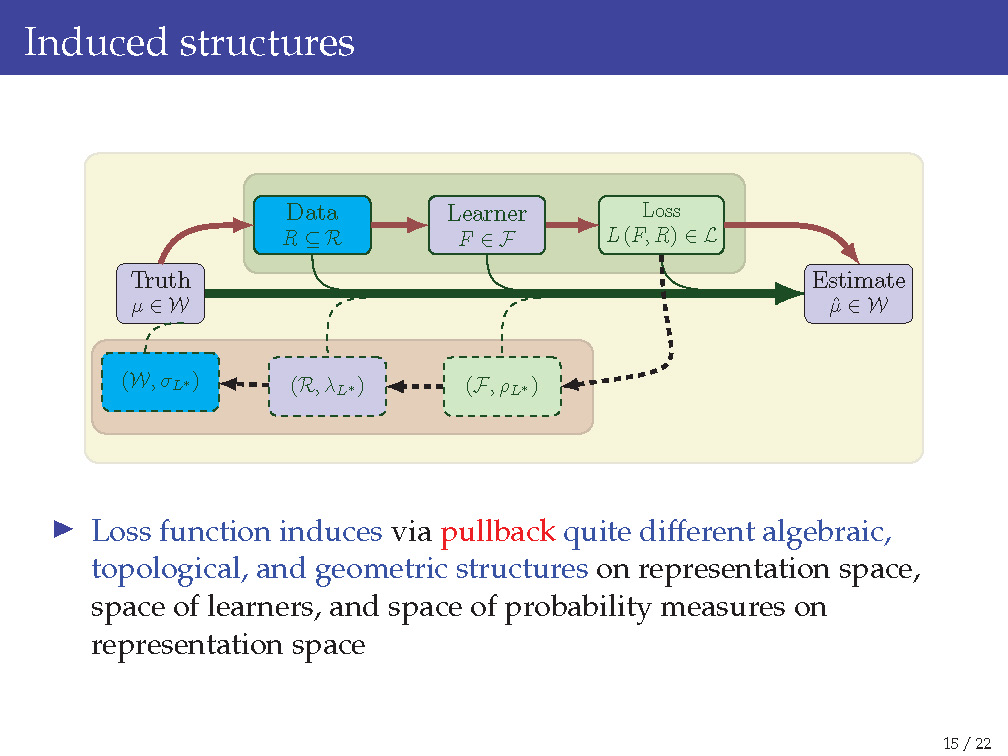
2. Induced geometric, topological, and algebraic structures
Before a loss function is used, a deep neural network ties the input and output spaces. However, once a loss function is optimized, it induces geometric, topological, and algebraic structures on the input space, space of functions for deep neural networks, and the output space, and the direction of “inducing structures” flows from the last layer to the fist layer of the network. This causes one main difficulty in understanding deep neural networks.
3. Concentrations of probabilities of random structures
Since the input is considered as random, every output or operation on the input produces random quantities unless they are trivial. Equivalently, the input carries only the empirical distribution. Therefore, the induced structures mentioned in Item 2 are random (unless they are trivial). Suppose the input has been generated by an unknown (e.g., the true) distribution, how “far” is each of these random structures based on the empirical distribution from those that are induced based on the true distribution? This is where concentration of probability plays its role.
4. Dual theory for operators
This is related to Item 2. It is known that dual theory of operators in mathematics often leads to more powerful characterization of an operator. Knowing that “back propagation” is currently the only feasible way to study the dynamics, i.e., the infinitesimal effects of composition of operations in a deep neural network, and that level sets of the loss function currently can only be studied layer-wise backwards, a dual theory that allows us to study these layer-wise forwards and that preserves properties of these operators would ultimately resolve the key challenge of looking inside a deep neural network.
D. A side project
- Geometric probability: Geometric probability is an exciting research the lies at the intersection of geometry and probability theory. This is a very challenging problem on the solution of a system of random linear equations. More information on it can be found at: https://mathoverflow.net/questions/202899/samuel-karlins-problem-probability-of-positive-solution-to-system-of-random-li
- Xiongzhi Chen (2015+): On Samuel Karlin’s problem of geometric probability and a variant. (In preparation.)